
Sequential UUID Generators
UUIDs are a popular identifier data type – they are unpredictable, and/or globally unique (or at least very unlikely to collide) and quite easy to generate. Traditional primary keys based on sequences won’t give you any of that, which makes them unsuitable for public identifiers, and UUIDs solve that pretty naturally.
But there are disadvantages too – they may make the access patterns much more random compared to traditional sequential identifiers, cause WAL write amplification etc. So let’s look at an extension generating “sequential” UUIDs, and how it can reduce the negative consequences of using UUIDs.
Let’s assume we’re inserting rows into a table with an UUID primary key (so there’s a unique index), and the UUIDs are generated as random values. In the table the rows may be simply appended at the end, which is very cheap. But what about the index? For indexes ordering matters, so the database has little choice about where to insert the new item – it has to go into a particular place in the index. As the UUID values are generated as random, the location will be random, with uniform distribution for all index pages.
This is unfortunate, as it works against adaptive cache management algorithms – there is no set of “frequently” accessed pages that we could keep in memory. If the index is larger than memory, the cache hit ratio (both for page cache and shared buffers) is doomed to be poor. And for small indexes, you probably don’t care that much.
Furthermore, this random write access pattern inflates the amount of generated WAL, due to having to perform full-page writes every time a page is modified for the first time after a checkpoint. (There is a feedback loop, as FPIs increase the amount of WAL, triggering checkpoints more often – which then results in more FPIs generated, …)
Of course, UUIDs influence read patterns too. Applications typically access a fairly limited subset of recent data. For example, an e-commerce site mostly cares about orders from the last couple of days, rarely accessing data beyond this time window. That works fairly naturally with sequential identifiers (the records will have good locality both in the table and in the index), but the random nature of UUIDs contradicts that, resulting in poor cache hit ratio.
These issues (particularly the write amplification) are a common problems when using UUIDs, and are discussed on our mailing lists from time to time. See for example Re: uuid, COMB uuid, distributed farms, Indexes on UUID – Fragmentation Issue or Sequential UUID Generation.
Making UUIDs sequential (a bit)
So, how can we improve the situation while keeping as much of the UUID advantages as possible? If we stick to perfectly random UUID values, there’s little we can do. So what if we abandoned the perfect randomness, and instead made the UUIDs a little bit sequential?
Note: This is not an entirely new idea, of course. It’s pretty much what’s described as COMB on the wikipedia UUID page, and closely described by Jimmy Nilsson in The Cost of GUIDs as Primary Keys. MSSQL implements a variant of this as newsequentialid (calling UuidCreateSequential internally). The solution implemented in the sequential-uuids extension and presented here is a variant tailored for PostgreSQL.
For example, a (very) naive UUID generator might generate a 64-bit value from a sequence, and appended additional 64 random bits. Or we might use a 32-bit unix timestamp, and append 96 random bits. Those are steps in the right direction, replacing the random access pattern with a sequential one. But there are a couple of flaws, here.
Firstly, while the values are quite unpredictable (64 random bits make guessing quite hard), quite a bit of information leaks thanks to the sequential part. Either we can determine in what order the values were generated, or when the values were generated. Secondly, perfectly sequential patterns have disadvantages too – for example if you delete historical data, you may end up with quite a bit of wasted space in the index because no new items will be routed to those mostly-empty index pages.
So what sequential-uuids extension does is a bit more elaborate. Instead of generating a perfectly sequential prefix, the value is sequential for a while, but also wraps around once in a while. The wrapping eliminates the predictability (it’s no longer possible to decide in which order two UUIDs were generated or when), and increases the amount of randomness in the UUID (because the prefix is shorter).
When using a sequence (much like nextval), the prefix value increments regularly after a certain number of UUIDs generated, and then eventually wraps around after certain number of blocks. For example we with use 2B prefix (i.e. 64k possible prefixes), incremented after generating 256 UUIDs, which means wrap-around after each 16M generated UUIDs. So the prefix is computed something like this:
prefix := (nextval('s') / block_size) % block_count
and the prefix length depends on block_count. With 64k blocks we only need 2B, leaving the remaining 112 bits random.
For timestamp-based UUID generator, the prefix is incremented regularly, e.g. each 60 seconds (or any arbitrary interval, depending on your application). And after a certain number of such increments, the prefix wraps around and starts from scratch. The prefix formula is similar to the sequence-based one:
prefix := (EXTRACT(epoch FROM clock_timestamp()) / interval_length) % block_count
With 64k blocks we only need 2B (just like for sequence-based generator), leaving the remaining 112 bits random. And the prefix wrap-around every ~45 days.
The extension implements this as two simple SQL-callable functions:
uuid_sequence_nextval(sequence, block_size, block_count)uuid_time_nextval(interval_length, block_count)
See the README for more details.
Benchmark
Time for a little benchmark, demonstrating how these sequential UUIDs improve the access patterns. I’ve used a system with a fairly weak storage system (3 x 7200k SATA RAID) – this is intentional, as it makes the I/O pattern change obvious. The test was a very simple INSERT into a table with a single UUID column, with a UNIQUE index on it. And I’ve done in starting with three dataset sizes – small (empty table), medium (fits into RAM) and large (exceds RAM).
The tests compare four UUID generators:
- random:
uuid_generate_v4() - time:
uuid_time_nextval(interval_length := 60, interval_count := 65536) - sequence(256):
uuid_sequence_nextval(s, block_size := 256, block_count := 65536) - sequence(64k):
uuid_sequence_nextval(s, block_size := 65536, block_count := 65536)
And the overall results (transactions per second) in a 4-hour run look like this:
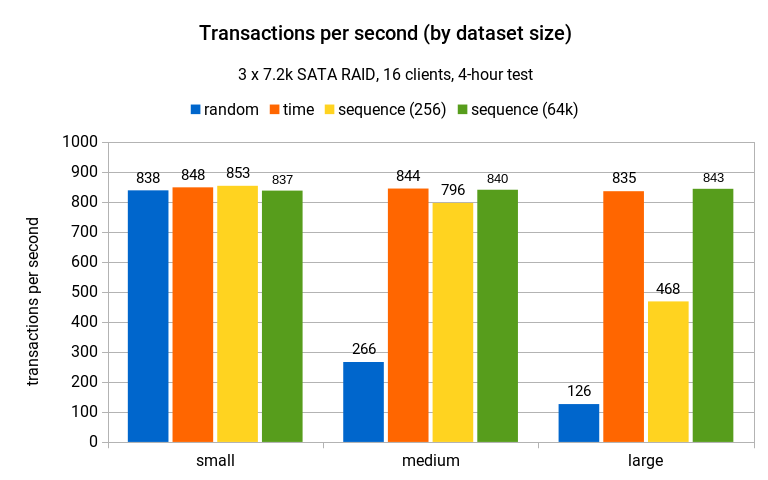
For the small scale there is almost no difference – the data fits into shared buffers (4GB) so there is no I/O trashing due to data being continuously evicted.
For the medium scale (larger than shared buffers, still fits into RAM) this changes quite a bit and the random UUID generator drops to less than 30% of the original throughput, while the other generators pretty much maintain the performance.
And on the largest scale the random UUID generator throughput drops even further, while time and sequence(64k) generators keep the same throughput as on the small scale. The sequence(256) generator drops to about 1/2 the throughput – this happens because it increments the prefix very often and ends up touching far more index pages than sequence(64k), as I’ll show later. But it’s still much faster than random, due to the sequential behavior.
WAL write amplification / small scale
As mentioned one of the problems with random UUIDs is the write amplification caused by many full-page images (FPI) written into WAL. So let’s see how that looks on the smallest dataset. The blue bar represents amount of WAL (in megabytes) represented by FPIs, while the orange bar represents amount of WAL occupied by regular WAL records.
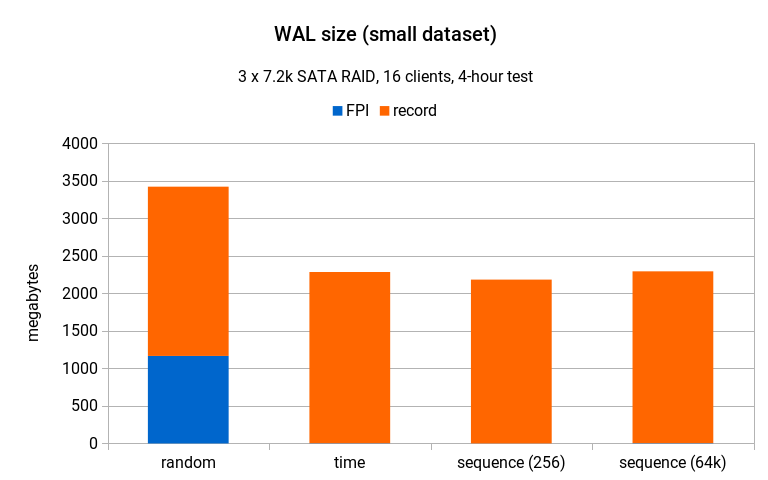
The difference is obvious, although the change in total amount of WAL generated is not huge (and the impact on throughput is negligible, because the dataset fits into shared buffers and so there’s no pressure / forced eviction). While the storage is weak, it handles sequential writes just fine, particularly at this volume (3.5GB over 4 hours).
WAL write amplification / medium dataset
On the medium scale (where the random throughput dropped to less than 30% compared to the small scale) the difference is much clearer.
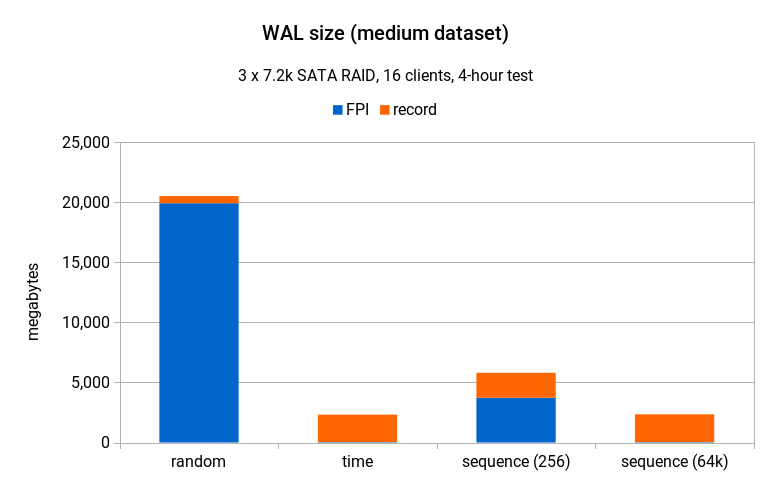
With random generator, the test generated more than 20GB of WAL, vast majority of that due to FPIs. The time and sequence(256) generators produced only about 2.5GB WAL, and sequence(64k) about 5GB.
But wait – this chart is actually quite misleading, because this compares data from tests with very different throughput (260tps vs. 840tps). After scaling the numbers to the same throughput as random, the chart looks like this:
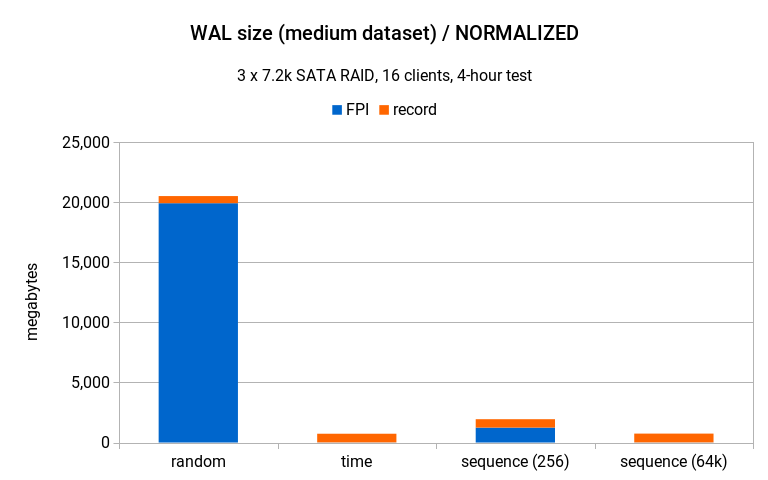
That is – the difference is even more significant, nicely illustrating the WAL write amplification issue with random UUIDs.
Large dataset
On the large data set it looks quite similar to medium scale, although this time the random generator produced less WAL than sequence(256).
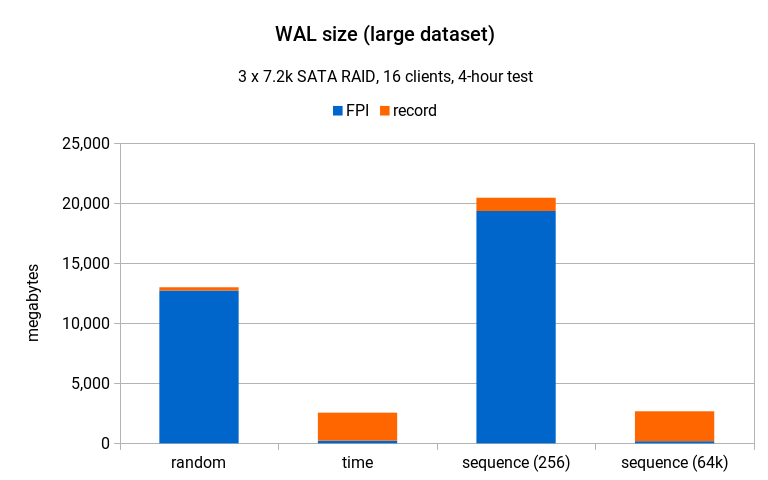
But again, that chart ignores the fact that the different generators have very different throughput (random achieved only about 20% compared to the two other generators), and if we scale it to the same throughput it looks like this:
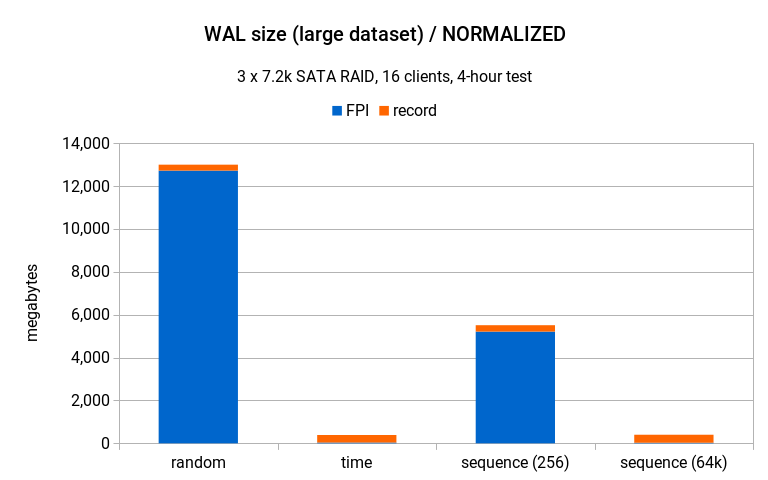
How is possible that sequence(256) produces more WAL compared to the random generator (20GB vs. 13GB), but achieved about 3x the throughput? One reason is that the amount of WAL does not really matter much here – SATA disks handle sequential writes pretty well and 20GB over 4 hours is next to nothing. What matters much more is write pattern for the data files themselves (particularly the index), and that’s much more sequential with sequence(256).
Cache hit ratio
The amount of WAL generated nicely illustrates the write amplification, and impact on write pattern in general. But what about the read access pattern? One metric we can look at is cache hit ratio. For shared buffers, it looks like this:
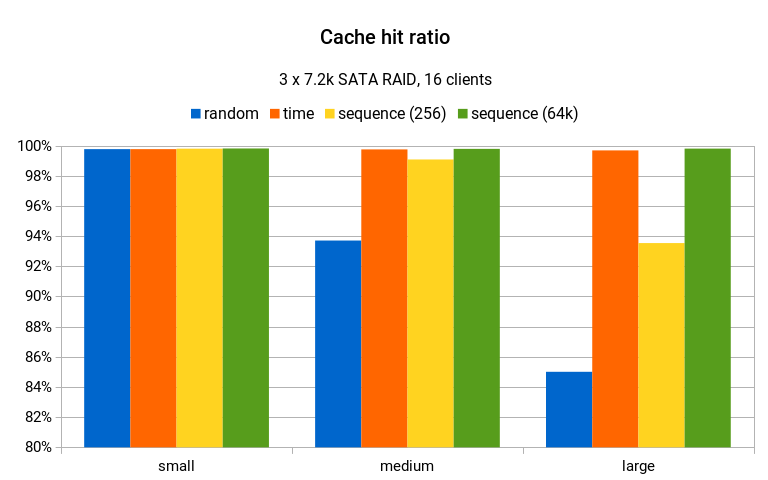
The best-performing generators achieve ~99% cache hit ratio, which is excellent. On the large data set, the random drops to only about 85%, while the sequence(256) keeps about 93% – which is not great, but still much better than 85%.
Another interesting statistics is the number of distinct index blocks mentioned in the WAL stream. On the largest scale it looks like this:
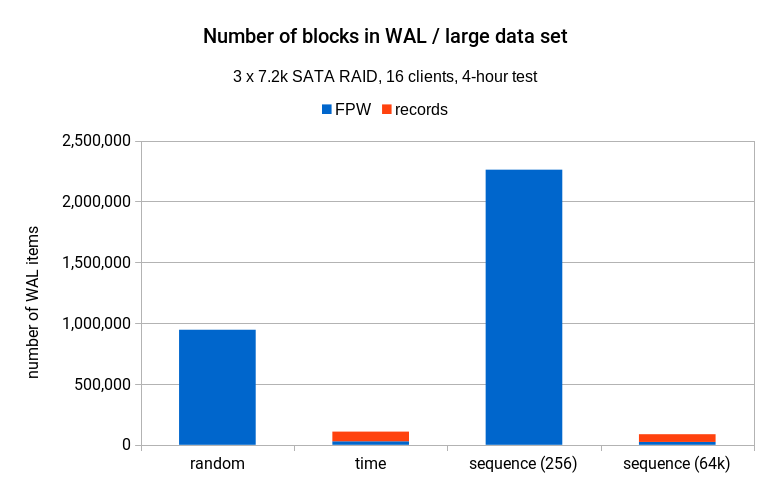
The chart may look a bit surprising, because the sequence(256) generator accesses more than twice the number of distinct blocks than random generator, while achieving 3x the performance at the same time. This may seem surprising at first, but is (again) due to the access pattern being much more sequential with sequence(256).
Choosing parameters
Both uuid_sequence_nextval and uuid_time_nextval functions have parameters, so it’s natural to ask how to pick the right parameter values. For example, in the tests presented in this post, uuid_sequence_nextval performed much better with block_size set to 64k (compared to 256). So why not to just use 64k all the time?
The answer is – it depends. 64k may work for busier systems, but for others it may be way too high. Moreover, you need to pick both parameters (block size and number of blocks) at the same time. Ask a couple of questions – how often should the generator wrap to 0? How many UUIDs does that mean? Then pick number of blocks high enough to slice the index into sufficiently small chunks, and pick the block size to match the desired wrap interval.
Summary
As illustrated by the tests, sequential UUIDs generators significantly reduce the write amplification and make the I/O patterns way more sequential and it may also improve the read access pattern. Will this help your application? Hard to say, you’ll have to give it a try. Chances are your database schema is more complicated and uses various other indexes, so maybe the issues due to UUIDs are fairly negligible in the bigger picture.
Very helpful.
Ported to java
https://gist.github.com/zenios/72dfaf3a931ad0e4e5e7031d950c3d9c
Thanks
Thanks. I guess that might be useful when generating UUIDs in the application and not the database.
Exactly. I use to generate ids on the application since it makes it easier having to install the default postgresql and not having to compile the extensions on each new db instance
I see that you have used SecureRandom in the code. Isn’t it too slow to be used frequently in the application?
Like most things, that depends on how much the application needs to use it.
I am confused — what happens when it wraps around? Do you get duplicates? Is another UUID random value chosen?
UUIDs don’t guarantee uniqueness, either. The UUID (v4) generation algorithm tries to maximize the time between duplicate/collision, given the number of bits in UUID. If the algorithm is implemented poorly (say if it’s buggy), you’d get collisions much sooner.
This implementation reduces the number of random bits available, so yes, in case of a wrap-around of sequential part there _may_ be a collision sooner compared to UUID. Hence the need for a Unique Index on UUID/seq-uuid column to reject duplicates.
No, you won’t get duplicates. Essentially, the sequential UUID is treated as having two parts (prefix,random) – only the prefix is sequential and wraps, but the rest is still random.
It does increase the likelihood of a collision compared to purely random UUIDs. The goal was to keep the prefix as short as possible, so keep them as random as possible. For example the default prefix is only 2B, so the remaining 14B are still random.
To put it into perspective, regular random UUIDs (v4) have 122 random bits, because 4 bits are used to store the UUID type. I have ignored this in the extension, but let’s say we also put 4 bits aside. That gives us 108 random bits with the 2B prefix (128-16-4).
Using the formula from the wikipedia UUID page, to get 50% probability of at least one collision, 122 random bits would need 2.71 * 10e18 values, while 108 random bits would need “only” 21 * 10e15 (i.e. 128x less). That’s still quite a bit of UUIDs, because even if you generate 1M UUIDs per second, it’ll take ~673 years to get there. Moreover, this ignores that the prefix is not fixed but changes and spreads the UUIDs (more or less uniformly) over the whole UUID space. So the actual collision probability is in fact much closer to the 122 bits.
Thanks for this post!
Is there a typo here :
> The sequence(256) generator drops to about 1/2 the throughput – this happens because it increments the prefix very often and ends up touching far more index pages than sequence(256)
Should be :
s/than sequence(256)/than sequence(64k)/ ?
Right. Thanks for noticing that, fixed.
One more small typo: … e-commerce site mostly ares about orders … (should be “cares about…”)?
Thanks, fixed.
I made a pure pgSQL implementation of the time-based generation method.
Hopefully this is useful for those of us using a service like AWS RDS where we can’t install C-based extensions.
https://gist.github.com/PachowStudios/f4c2e26829d82ed8d38eb5e6e6374ec2
My two cents:
Don’t bother. Just generate it in the application This way your application also becomes more db agnostic.
FYI, The Amazon AWS RDS offering includes the `uuid-ossp` extension usually included with Postgres.
For a list of provided extensions, see: https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/CHAP_PostgreSQL.html#PostgreSQL.Concepts.General.FeatureSupport.Extensions
This is great! They are sequential, but are they sortable? Can I run:
“`
DECLARE
last_created_at integer;
BEGIN
FOR (
SELECT uuid, created_at FROM my_table_with_time_based_seq_ids t
SORT BY uuid ASC
) LOOP
IF NOT last_created_at < created_at THEN
RAISE EXCEPTION 'this is not as sequentially sortable as i would like';
END IF;
last_created_at := created_at;
END FOR;
END;
“`
without exception?
No, they won’t be strictly monotonic.
Neither is a regular
SEQUENCEbecause the order of ID generation differs from the order of commit.Pretty much nothing will satisfy that requirement except a lock-based counter generator with no concurrency, i.e. gapless sequence generation.
Working Java implementation by the ‘uuid-creator’ project : https://github.com/f4b6a3/uuid-creator#short-prefix-comb-non-standard
There’s also this UUID “v6” proposal floating around now: http://gh.peabody.io/uuidv6/
It’s more monotonic than the proposal here (but obviously not strictly so, as Craig has already explained above), so makes different trade-offs. I found it interesting enough and wanted a pure PG implementation to experiment, so ported the MySQL one from the proposal here: https://gist.github.com/bjeanes/c1d751395effec72ac6631211cb84718
The UUID v6 proposal looks interesting, thanks for the link.
I think the “perfectly monotonic” nature will cause issues after DELETE (because we’ll never reuse the space in index on the UUID). That’s why the sequential UUIDs here cycle regularly, pretty much. Similarly, the ability to extract the timestamp from the UUID seems somewhat useless and cumbersome for most applications – it’s more convenient to have a separate column with ability to specify precision, direct support from ORM etc.
Does this have any performance advantages over ULIDs? https://github.com/ulid/spec
Right now I’m leaning in favor of ULIDs because they’re simple to generate clientside – see all the implementations in the above link. The advantages of your extension are the ability to control the block_size and block_count, as well as interval_length and interval_count. I’m not sure if these advantages outweigh the ability to easily generate an ID clientside however. (ULIDs do offer the ability to generate an ID for a specific time, but it doesn’t have as many options as what your extension offers.)
Changing topics, it’s important to note that neither your extension (or ULIDs) are RFC 4122 compliant. Mixing either with “normal” UUIDs has an increased likelihood of collisions. To quote Stephen Cleary:
> This means that newsequentialid() GUIDs are not RFC 4122 compliant! As a result, GUIDs from newsequentialid() have a higher likelihood of colliding with RFC 4122 compliant GUIDs such as sequential or random GUIDs.
https://blog.stephencleary.com/2010/11/few-words-on-guids.html
If I understand the ULID specification correctly, it does not “cycle” through the space. So if you delete a lot of historical data, it’ll still have issues with space in indexes wasted forever (because new data will never go to the older empty parts).
Is there a way to reclaim that space in the index? I am also considering using the extension (or rather a pl/pgsql implementation of it) vs a ulid implementation (also in pl/pgsql since you can’t have C extensions on RDS). While I don’t plan on deleting a lot of historical data it would be nice to have to have a benchmark that compares the two methods.
I’ve been using https://github.com/tanglebones/pg_tuid for a while. The C version can be made faster, once pg13 is stable I hope to get back to it.
Thanks for this post!
The results are very helpful indeed!
I tried to reproduce the behaviour of the random UUID (uuid_generate_v4) as far as the TPS on my local PostgreSQL but with no success.
shared_buffers = 512mb
ram = 16gb
cpu = 4cores
disk = SSD
The dataset size do you refer to the data that are populated in the table before running the tests?
Thanks
Yes, the data was populated before starting the benchmark.