
repmgr 3.2 is here with Barman support and Brand New High Availability features
repmgr 3.2 has recently been released with a number of enhancements, particularly support for 2ndQuadrant’s Barman archive management server, additional cluster monitoring functionality and improvements to the standby cloning process.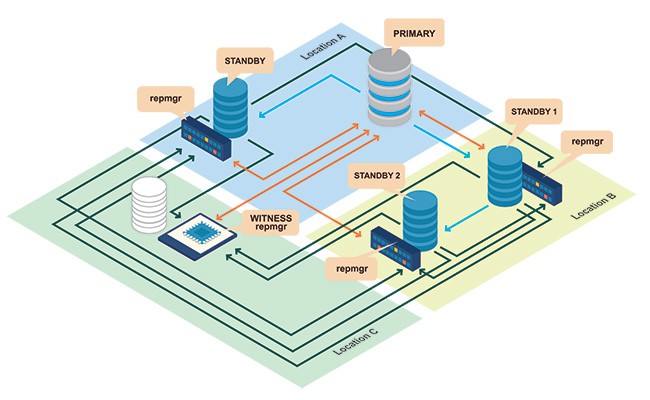
One aim of this release is to remove the requirement to set up passwordless SSH between servers, which means when using repmgr’s standard functionality to clone a standby, this is no longer a prerequisite. However, some advanced operations do require SSH access to be enabled.
Barman support
repmgr 3.2 can now clone a standby directly from the Barman backup and recovery manager. In particular it is now possible to clone a standby from a Barman archive, rather than directly from a running database server. This means the server is not subjected to the I/O load caused by a backup, and there’s no need to manage WAL retention on the database server other than to ensure WALs are archived to Barman. The standby can also use the Barman archive as a fallback source of WAL files in case streaming replication is interrupted.
To clone from barman, the following prequisites must be met:
- the Barman server’s host name must be set in repmgr.conf with the parameter barman_server
- the Barman server must be accessible by SSH
- the name of the server configured in Barman is equal to the cluster_name setting in repmgr.conf
- Barman must have at least one valid backup for this server
With barman_server set, repmgr will automatically attempt to clone from Barman. --without-barman overrides this behaviour and allows repmgr to clone directly from another PostgreSQL server. See the README for further details. This feature was implemented by my colleague Gianni Colli.
Cluster status monitoring
Previous repmgr versions provided the command repmgr cluster show, which displays a simple overview of the cluster status as seen from the node it was executed on. However, this only provides a partial picture of the cluster’s state – in particular it could indicate that a node appears to be down, even though the node is running and is reachable from other nodes.
repmgr 3.2 provides two new commands to provide a global overview of the cluster, designed by my colleague Gianni Colli. repmgr cluster matrix executes repmgr cluster show on each node in the cluster and arranges the results in a matrix; a two-dimensional view compared to repmgr cluster show‘s single dimension.
Given a simple 3-node cluster, repmgr cluster show executed on node2 shows the following output:
[postgresql@node2 ~] $ repmgr -f /etc/repmgr/9.6/repmgr.conf cluster show Role | Name | Upstream | Connection String ----------+-------|----------|-------------------------------------------------------- * master | node1 | | host=node1 user=repmgr dbname=repmgr connect_timeout=2 standby | node2 | node1 | host=node2 user=repmgr dbname=repmgr connect_timeout=2 FAILED | node3 | node1 | host=node5 user=repmgr dbname=repmgr connect_timeout=2
This implies node3 is down, but in fact just the network connection between node2 and node3 is interrupted. repmgr cluster matrix provides a more nuanced overview:
$ repmgr -f /etc/repmgr/9.6/repmgr.conf cluster matrix Name | Id | 1 | 2 | 3 ------+----+----+----+---- node1 | 1 | * | * | * node2 | 2 | * | * | x node3 | 3 | ? | ? | ?
An asterisk (*) shows that a connection is possible between two nodes, an ‘x’ shows that the connection is not possible, and ‘?’ shows that connection status is unknown. Here we see that node2 cannot connect to node 3, but node 3’s connection status is still partially unknown – more precisely, we’re still unsure which other nodes node3 can connect to.
repmgr cluster crosscheck provides this information – as the name implies, it cross-checks connections between each node and provides a 3-dimensional overview of all connections in the cluster:
$ repmgr -f /etc/repmgr/9.6/repmgr.conf cluster crosscheck Name | Id | 1 | 2 | 3 ------+----+----+----+---- node1 | 1 | * | * | * node2 | 2 | * | * | x node3 | 3 | * | x | *
Here we see that node3 can connect to itself and node1, which indicates that while the replication cluster is currently working, there’s a connection issue between node2 and node3.
These commands require password-less ssh connections between all nodes.
Improvements to configuration file copying
On some distributions such as Debian/Ubuntu, PostgreSQL’s configuration files are kept outside of the PostgreSQL data directory and won’t be copied as part of the standard standby cloning process. Previous repmgr versions did attempt to copy the standard configuration files (postgresql.conf, pg_hba.conf and pg_ident.conf), but none of the additional files included from postgresql.conf.
From 3.2 repmgr provides the option --copy-external-config-files to instruct repmgr to attempt to copy configuration files located outside the data directory. repmgr will also detect any files included from the main postgresql.conf file and copy these as well. Note, however, that any files which do not contain active configuration settings will not be detected.
By default, repmgr will attempt to copy configuration files to the same location on the standby being cloned as on the original server; --copy-external-config-files=pgdata will place them into the PostgreSQL data directory.
This option replaces the earlier --ignore-external-config-files, and requires passwordless SSH access to the server being cloned from.
Other improvements to standby clone
By default, cloning will be carried out with pg_basebackup’s --xlog-method set to stream – this ensures that WAL files are copied while the backup is being taken, rather than fetched afterwards (when required files may already have been removed). This option can be overridden by adding --xlog-method=fetch to pg_basebackup_options in repmgr.conf.
From PostgreSQL 9.6, if replication slots are requested (and --xlog-method is not explictly set to fetch in repmgr.conf), repmgr will use pg_basebackup’s new -S/--slot option to stream WAL from the same replication slot which the standby will later connect to; ensuring the server does not remove any necessary WAL data in the time between the end of the standby clone operation and the start of streaming replication.
This also means that repmgr no longer requires that wal_keep_segments is set on the server being cloned from, except in corner cases where pg_basebackup’s --xlog-method is set to fetch, replication slots are not in use and no alternative source of WALs was defined with restore_command.
Additionally, repmgr will now actively check that there are sufficient free walsenders available on the source server before beginning the clone operation.
Other new commands
Witness server administration has been enhanced with the commands witness register and witness unregister, the former enabling an existing, running database to be registered as a witness server.
Additionally, the commands standby unregister and witness unregister can be used to unregister a server that is not running (previously this required direct manipulation of the repmgr metadata table); these can be executed on any running node by providing the ID of the node to unregister with the --node option.
repmgrd improvements
Previous repmgrd versions controlled the PostgreSQL server with the standard pg_ctl command. However, this can cause issues with OS-level process management, such as that provided by systemd. To explicitly specify the service control command to be used in place of pg_ctl, the following repmgr.conf configuration settings are available:
- service_start_command
- service_stop_command
- service_restart_command
- service_reload_command
- service_promote_command
repmgrd will now refuse to start on a node which is marked as inactive in the repmgr metadata, if failover is set to automatic in repmgr.conf. As repmgrd does not consider an inactive node as a promotion candidate, this will prevent repmgrd from appearing to offer failover for the node when it will never be promoted.
Leave a Reply
Want to join the discussion?Feel free to contribute!